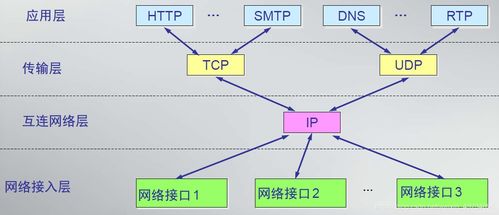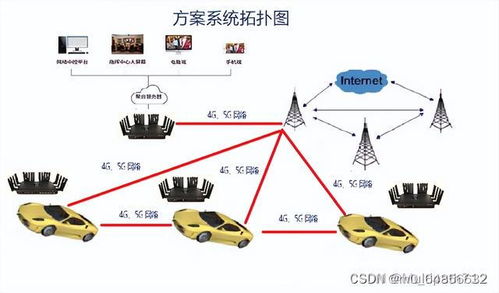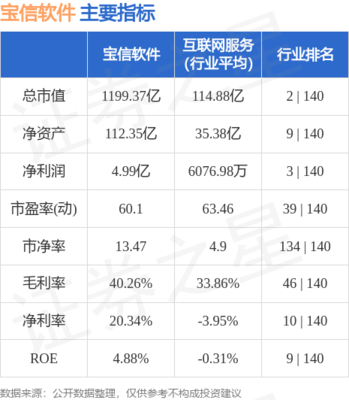
通信系統開發與集成領域迎來多重政策與技術突破,行業景氣度顯著提升,市場分析普遍認為,以下三大利好因素有望在下周催化相關板塊走強。
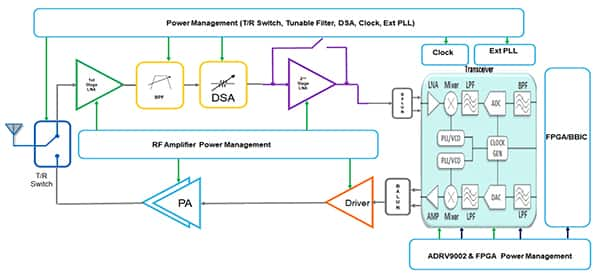
政策層面持續加碼。國家近期明確提出加快新型基礎設施建設,其中5G-A(5G-Advanced)與6G研發被置于核心位置。這不僅意味著未來幾年網絡建設投資將保持高位,更預示著從標準制定、設備研發到系統集成的全產業鏈將迎來新一輪需求爆發。特別是對于具備整體解決方案提供能力的系統集成商,其承接大型項目、實現軟硬件協同的優勢將更加凸顯。
技術融合與場景落地加速。當前,通信系統正與人工智能、算力網絡深度融合,催生出智能運維、網絡自動化、低空經濟通信保障等全新應用場景。領先的開發集成企業通過將AI算法嵌入網絡管理與優化環節,大幅提升了系統效率和可靠性,從而在智慧城市、工業互聯網等重大項目招標中獲得先機。這種“通信+AI”的融合解決方案,正成為企業重要的業績增長點和估值支撐。
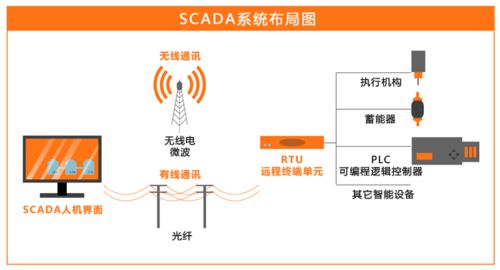
市場需求結構升級。傳統運營商的資本開支正從廣覆蓋轉向深度優化和垂直行業應用。衛星互聯網、物聯網等新興領域對定制化、高可靠通信系統的需求激增。這要求開發集成商不僅提供產品,更要提供從設計、部署到運維的全周期服務。具備核心技術積累和豐富項目經驗的頭部企業,其訂單能見度和客戶黏性正在增強,業績確定性較高。
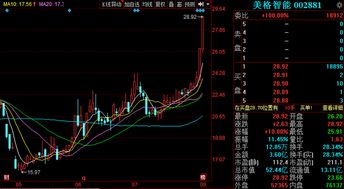
在政策東風、技術迭代與需求升級的三重驅動下,通信系統開發與集成行業的基本面持續向好。資本市場已開始重新評估該賽道的成長潛力,部分技術領先、訂單飽滿的上市公司,其股價在下周有望對上述利好做出積極反應,投資者可重點關注其在核心技術、市場布局及業績兌現方面的具體表現。